Server Configuration
This page covers advanced configuration options. For basic settings that have to be specified upon installation, please refer to the mandatory configuration section of the previous page.
Changing the Configuration¶
The iserver application provides a variety of configuration options that can
be set via a text file named application.properties. This configuration file can be located either in the same folder as
the server executable (iserver) or in a dedicated /config subdirectory of the current working
directory. If both are present, the latter option has a higher priority, which allows
different users to easily start the server application with their own configuration.
Info
It is required to restart the server after changing the configuration file for the changes to take effect.
Scheduler and Job-Splitting Parameters¶
The first and most important setting concerns the cluster resource management system (scheduler) in use. If this is not SGE, this is a mandatory setting, as described in the sections for the respective scheduling systems (PBS/TORQUE, Slurm, UGE).
# Possible values: slurm, sge-cmd, sge, uge, pbs, torque
scheduler=sge
The next setting specifies how many resource manager slots should be used for a single virtual screening sub-job. This usually translates to processor cores. This setting can be overridden by the user when sending a remote screening request from LigandScout or KNIME.
scheduler.number.processors.screening=4
Similar to virtual screening, it is also possible to specify how many resource manager slots should be used for a single conformer generation sub-job. This setting can be overridden by the user when sending a remote conformer generation request from LigandScout or KNIME.
scheduler.number.processors.confgen=2
All supported schedulers allow to specify a priority when submitted a new job into the queue. The higher this value is, the less priority the job has. In the case of SGE, PBS, and TORQUE the value has to be in the range 0 to 1023. The iserver application will set the given value as negative priority, no matter which sign is used.
Reference
Cited from man qsub:
Defines or redefines the priority of the job relative to other jobs. Priority is an integer in the range -1023 to 1024. The default priority value for jobs is 0.
This statement is valid for SGE, PBS, and TORQUE.
In the case of SLURM, the value will be set via the --nice parameter when submitting a new job. A value from 0 (highest priority) to 2147483645 (least priority) is allowed. The iserver application will set the given value as positive priority, no matter which sign is used.
scheduler.priority=0
This setting can be overridden by the user when sending a remote screening request from LigandScout or KNIME.
Info
It is not possible to increase the job priority with this setting. It is recommended to leave this value at 0 or increase it when jobs started via iserver should have less than default priority.
When using an SGE resource manager, it is required to specify a correct parallel environment. The iserver application does not support MPI, therefore a shared-memory environment has to be set. Usually, this is smp, which is also the default setting in the iserver configuration:
scheduler.sge.parallel.environment=smp
The queue that should be used for submitting jobs to SGE can also be set. The specified queue name will be used when detecting the number of currently available slots. Many SGE installations use only one queue (all.q), in this case, it is not required to change the iserver configuration.
scheduler.sge.queue=all.q
The next option can be used to pass any arguments to an SGE scheduling system.
scheduler.sge.option.string=
This option is used to set the SLURM partition used for job submission. If no value is set, jobs will be submitted to the default partition.
scheduler.slurm.partition=
This option can be used to pass any arguments to a SLURM scheduling system.
# e.g: scheduler.slurm.option.string=--time=24:00:00 --nodelist=node01
scheduler.slurm.option.string=
The iscreen command-line tool is used for submitting virtual screening jobs to the cluster resource manager. The following options can be used for specifying the resources these iscreen jobs should be allowed to consume. The practical evaluation has shown that the best performance is usually achieved when using around 1.5 to 2 times as many iscreen cores as scheduler slots. This is because not all jobs are always consuming 100% of the resources that are assigned to them.
The iscreen.memory should be set to around 1.5 times the amound of iscreen.amount.cores.
# iScreen
iscreen.amount.cores=6
iscreen.memory=8
Info
These values should only be changed in conjuction with scheduler.number.processors.screening.
Similar to iscreen, it is also possible to configure the resource usage of idbgen sub-jobs, which is used for conformer generation.
# idbgen
idbgen.memory=4
idbgen.memory.slaves=3
Info
These values should only be changed in conjunction with scheduler.number.processors.confgen.
The iserver application is capable of splitting screening experiments and conformer generation jobs into multiple smaller sub-jobs. The following setting specifies how many compounds should be screened in a single virtual screening sub-job.
# Job Splitting
job.splitting.max.chunk.size= 2000000
The following figure shows the exploitation of multiple distributed-memory nodes via job splitting. If the database is screened using two separate sub-jobs, it is possible to exploit the full HPC cluster:
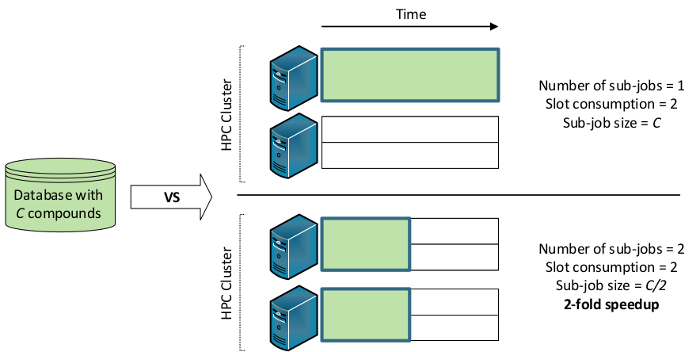
This setting can be overridden by the user when sending a remote screening request from LigandScout or KNIME. By default, splitting is only done per database chunk.
Similar to virtual screening, job splitting is also done for conformer generation. The following setting specifies how many input compounds should be used for each idbgen sub-job.
job.splitting.max.chunk.size.confgen = 10000
This setting can be overriden by the user when sending a remote conformer generation request from LigandScout or KNIME.
Data Management¶
# directories to search for conformer generation input files (*.sdf, *.smi, *.mol2,...)
# multiple directories can be set separated by comma (,)
# Supports '*' and <user> as wildcard options. The latter is substituted with the user's username e.g. /shared/data/*/molecules,/home/<user>/sdf
job.confgen.input.directories=
job.confgen.input.recursive=true
Use this setting to mitigate the need to upload input files for remote conformer generation jobs. Instead of uploading, this setting allows a user to select an input file that exists within the monitored folders. If job.confgen.input.recursive is set to true (default), subdirectories of the given locations will also be searched for viable molecule input files.
merge.confgen.databases=false
This setting allows to enable automatic merging of output database chunks after a remote conformer generation job has finished. Per default, each sub-job creates one database chunk. Those are not merged, but only placed into a common folder.
move_finished_jobs=false
If this parameter is set to true, the files belonging to specific virtual screening or conformer generation jobs are moved to a user-defined location (see below), after the job is completed.
Info
For conformer generation, this does not concern the output screening databases, but only the log and input files. The location of the output databases is given with job.confgen.databases.directory. However, in the case of virtual screening, this also concerns the output files (i.e. hit lists).
If move_finished_jobs is set to true, the below setting specifies the location to which the files associated to jobs are moved.
# Directory to which finished and cancelled jobs will be moved if
# move_finished_jobs is set to true.
# The <user> placeholder will be replaced with the name of the
# user who started the job. Note that the server application has to be able to
# write to the respective directorie(s).
finished_jobs_directory=/home/<user>/jobs
Logging properties¶
It is possible to specify the directory that iserver will use for storing log files. This is especially important if iserver does not have write access to its own installation directory.
logging.directory=./logs
The remaining logging properties are mainly relevant for developers who wish to see more detailed logging output.
# DEBUG setting will produce A LOT more logging output,
# interesting only for developers
logging.level.root=INFO
logging.level.org.springframework.web: WARN
logging.level.com.tupilabs.pbs: WARN
logging.level.ilib.server.grid.slurm: WARN
Database properties¶
These settings allow to specify which relational database should be used for storing the metadata associated to virtual screening and conformer generation jobs. By default, an embedded H2 database is used, which requires no further configuration. The iserver application has also been tested extensively with MySQL, but should work with any relational database management system.
spring.datasource.url=jdbc:h2:./database/ilib-server;AUTO_SERVER=TRUE;MVCC=true
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=admin
spring.datasource.password=password
spring.jpa.generate-ddl=true
spring.jpa.show-sql=false
spring.jpa.hibernate.ddl-auto=create-update
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.use-new-id-generator-mappings=true
spring.h2.console.enabled=true
spring.h2.console.path=/console/
Tomcat properties¶
The first set of Tomcat properties specify how the embedded web server should log the incoming requests. The default settings should be fine for most users.
server.tomcat.basedir=./tomcat/tomcat-logs
server.tomcat.accesslog.enabled=true
server.tomcat.accesslog.pattern=%t %a "%r" %s (%D ms)
The following properties specify the maximum file size that can be uploaded to iserver.
The default values should be increased if large input files for conformer generation have to be uploaded. In case existing screening databases (.ldb) should be uploaded, the values might have to be increased substantially (e.g. 32768MB). Please make sure that the server host provides enough disk space if large uploads are intended.
spring.http.multipart.max-file-size=1024MB
spring.http.multipart.max-request-size=1024MB
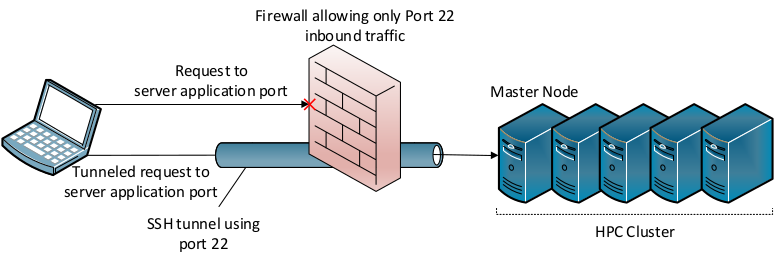
The following setting specifies which port iserver listens on for new job requests. Please note that it is not a problem if the firewall blocks access to this port. All traffic uses the SSH port, as illustrated in the figure below.
# Port on which the server application will listen for requests. Default: 8080
server.port = 8080
Testing Procedures¶
On startup, iserver will try to validate the settings in application.properties. The first setting in this section disables this validation completely.
# If true, all testing procedures done on startup will be skipped
testing.skip=false
Info
Note that properties can be overridden from the command-line. To start without testing procedures, run iserver --testing.skip=true
If you only want to disable paths testing, use this option:
# If true, and test.skip is set to false, iserver will validate path settings on startup
testing.paths=true
The next option can be used to disable the validation of the schedule settings.
# If true, and test.skip is set to false, iserver will try to access the scheduling system on application startup
# This is done by retrieving usage information
testing.scheduler=true
By default, iserver will terminate when an invalid setting has been found. In some circumstances, it can be helpful to proceed with invalid settings:
# If true, the server process will terminate when an invalid setting has been found.
# Setting this to false can be useful for debugging purposes, or when a specific invalid setting is not required for your use cases.
testing.quit-on-error=true
Default Configuration¶
The iserver application comes with an embedded default configuration. This means, that even if you delete settings keys in the application.properties file within the iserver installation folder, the default configuration still exists as a fallback.
Below, you can see the complete default configuration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 | |